
- Converting drivers to the new wifi stack
- GNOME
- How to enable back and forward buttons on a 5 button mouse
- How to increase ulimit with rc.conf
- Installation on UEFI systems
- Testing new wifi
- Wifi renewal on hg
- abi
- amazon ec2
- attic museum
- ?blog
- bugtracking
- certctl-transition
- comments
- curses in netbsd
- dev
- developer key signing
- donations
- events
- examples
- features
- github
- gitsofar
- grub2
-
?guide
- audio
- bluetooth
- boot
- build
- carp
- ccd
- cgd
- cons
- dns
- edit
- exinst
- fetch
-
gen index.sh
- exinst bios-disk.eps
- exinst bootblocks.eps
- exinst bootcode-up.eps
- exinst bootselect.eps
- exinst cdrom.eps
- exinst cipher.eps
- exinst completed.eps
- exinst configure.eps
- exinst confirm.eps
- exinst disk-geometry.eps
- exinst disklabel-add.eps
- exinst disklabel-add2.eps
- exinst disklabel-change.eps
- exinst disklabel-partition-editor.eps
- exinst disklabel-partitions.eps
- exinst disklabel.eps
- exinst diskname.eps
- exinst extraction-complete.eps
- exinst fdisk-bootmenu.eps
- exinst fdisk-finished.eps
- exinst fdisk-size.eps
- exinst fdisk-type.eps
- exinst fdisk.eps
- exinst ftp-cfg.eps
- exinst ftp-cfgok.eps
- exinst ftp-dhcp.eps
- exinst ftp-if.eps
- exinst ftp-mediatype.eps
- exinst ftp-save-settings.eps
- exinst ftp-src.eps
- exinst install-type.eps
- exinst keyboard.eps
- exinst language.eps
- exinst last-chance.eps
- exinst main.eps
- exinst mbr.eps
- exinst medium.eps
- exinst mount-msdos.eps
- exinst mount-partition.eps
- exinst mount.eps
- exinst nfs-example.eps
- exinst nfs.eps
- exinst passwd.eps
- exinst passwd2.eps
- exinst reallyformat.eps
- exinst reboot.eps
- exinst select disk.eps
- exinst select medium.eps
- exinst sets.eps
- exinst shell.eps
- exinst timezone.eps
- exinst verbosity.eps
- install bootblocks.eps
- install install-type.eps
- install medium.eps
- install verbosity.eps
- ipv4-en-0bits.eps
- ipv6-en-0bits.bmp
- ipv6-en-0bits.eps
- ipv6-en-1scene.bmp
- ipv6-en-1scene.eps
- ipv6-en-2tunnel.bmp
- ipv6-en-2tunnel.eps
- ipv6-en-3adr.bmp
- ipv6-en-3adr.eps
- ipv6-en-4scope.bmp
- ipv6-en-4scope.eps
- ipv6-en-5forward.bmp
- ipv6-en-5forward.eps
- ipv6-en-6adrformats.bmp
- ipv6-en-6adrformats.eps
- lvm.eps
- mail1.bmp
- mail1.eps
- net-pic1.bmp
- net-pic1.eps
- net-pic2.bmp
- net-pic2.eps
- net1.bmp
- net1.eps
- part.bmp
- part.eps
- part.pdf
- raidframe awardbios1.eps
- raidframe awardbios2.eps
- raidframe diagrams.dia
- raidframe r1r-pp1.eps
- raidframe r1r-pp2.eps
- raidframe r1r-pp3.eps
- raidframe r1r-pp4.eps
- raidframe raidl1-diskdia.eps
- upgrading complete.eps
- upgrading confirm.eps
- upgrading fsck.eps
- upgrading main.eps
- upgrading postinst.eps
- upgrading select-disc.eps
- index
- index bare
- inetd
- inst
- inst-media
- intro
- kernel
- linux
- lvm
- misc
- net-intro
- net-practice
- net-services
- pam
- raidframe
- rc
- rmmedia
- toc order
- tuning
- updating
- upgrading
- veriexec
- x
- hackathon
- hackathon2016
- htdocs migration
- ikiwiki
- index
- individual-software-releases
- ?infra
- java
- kerberos
- kernel debugging with qemu
- kernel dir
- kyua
- languages
- laptops
- light-desktop
- mailing-lists
- matrix
- netbsd-code-chat
- netbsd kernel development setup
- nsps
- nytprof.out.19600
- nytprof.out.7195
- opensoundsystem
-
pkgsrc
- faq
- frequently asked questions from pkgsrc developers
- gcc
- hardening
- how to clean all pkgsrc work directories
- how to convert autotools to meson
- how to do an unprivileged bulk build on irix
- how to do an unprivileged bulk build on solaris
- how to install a lamp server
- how to install a mysql server
- how to install a postgresql server
- how to install modular xorg
- how to save your packages
- how to update a package in pkgsrc
- how to upgrade packages
- how to use pkg options with pkgsrc
- how to use pkgsrc
- how to use pkgsrc mounted over nfs
- how to use pkgsrc on aix
- how to use pkgsrc on hp-ux
- how to use pkgsrc on irix
- how to use pkgsrc on linux
- how to use pkgsrc on osf1
- how to use pkgsrc on solaris
- intro to packaging
- macos porting notes
- macosx tiger powerpc
- mk.conf
- remote
- solarish
- targets
- texlive
-
ports
- aarch64
- acorn26
- acorn32
- algor
- alpha
- amd64
- amiga
- amigappc
- arc
- atari
- bebox
- cats
- cesfic
- cobalt
- dreamcast
- emips
- epoc32
- evbarm
- evbmips
- evbppc
- evbsh3
- ews4800mips
- fusion arm
- hp300
- hp300faq
- hp700
- hpcarm
- hpcmips
- hpcsh
- hppa
- hppafaq
- i386
- ia64
- ibmnws
- iyonix
- landisk
- luna68k
- mac68k
- macppc
- mipsco
- mmeye
- mvme68k
- mvmeppc
- netwinder
- news68k
- news68kfaq
- newsmips
- next68k
- next68kfaq
- ofppc
- pmax
- prep
- qemu riscv
- riscv
- rs6000
- sandpoint
- sbmips
- sgimips
- sh3
- shark
- sparc
- sparc64
- sun2
- sun3
- vax
- vax-models
- x68k
- xen
- zaurus
-
projects
- all
- all-flat
- application
- code-in
- code-in 2012
- done
- funded
- gsoc
- ideas
-
?project
- 802.11-scheme
- 802.11-transmit-queue
- Add Argon2 password hashing
- Add UEFI boot options
- Convert a Wi-Fi driver to the new Wi-Fi stack
- Fix resize_ffs(8) for FFSv2 file systems
- Make signed binary pkgs for NetBSD happen
- Update web firewall documentation from ipfilter to npf
- afl filesystem fuzzing
- aio
- altq
- anita-vms
- apropos
- atf-sql-backend
- atomic fifo lifo queues
- atomic pcq
- atomic radix patricia trees
- audioviz
- aws-images
- benchmark
- better tabular stats
- binary compat puffs backend
- brcmsmac-brcmfmac-wifi-driver
- bsdmake-enhancements
- buffer-flowcontrol
- buffer-queue
- build-kernel-pie
- build-system-rework
- bulktracker
- c refactoring aid
- clang-format
- common-boot-cfg
- compat android
- compat linux arm64
- compressed-cache
- convert-docs-to-asciidoc
- cross-bootstrapping
- cross nb pkgsrc
- cvs-migration
- deadlock-detector
- debpkg
- desktop-infrastructure
- disk-removal
- donations
- dotdot
- download-isolation
- drm compat
- dtrace-syscall
- efi
- email digester
- enlightenment
- ext3fs
- ext4fs
- fast-time
- fast protocol
- ffs-defrag
- ffs-discard
- ffs-fallocate
- findoptimizer
- flash-translation
- flite
- fonthandling
- fs-services
- fs scrub flags
- fsck udf
- fullfs
- gio-file-monitoring
- gomoku-brain
- hammer
- if poll
- ikev2
- imapfs
- improve-caching
- inetd-enhancements
- ipv6-stable-privacy-addresses
- iscsictl
- iso9660-extensions
- java-swt
- jfs
- jtag kit
- kasan
- kernel components
- kernel continuations
- kernel setroot tests
- kernel udp timestamping
- kernfs-rewrite
- kismet
- kqueue-dirnotify
- language-neutral-interfaces
- launchd-port
- lazy receive
- ledapi
- lfs-quotas
- libcurses-automated-test
- libfuzzer
- libintl
- libpktlatency
- libvirt
- linux timer
- linuxtest
- live-upgrade
- livecd-install
- logwatch
- lpr
- lua bindings chicken and egg
- make-kqueue
- make system(3) and popen(3) use posix_spawn(3)
- maxphys-dynamic
- mesavulkan
- microblaze
- mlockin
- mmu-less
- move-beyond-twm
- mpsafe net driver
- netbsd on microsoft azure
- netpgpverify
- new-automounter
- nexthop cache
- nfsv4
- npf improvements
- npf user group filtering
- npf web ui
- opencrypto swcrypto
- optional tcp syncache
- page queues
- pam-tests
- performance regress
- pkgin improve
- pkgsrc-chromium
- pkgsrc-create-other-packages
- pkgsrc-debugpkg
- pkgsrc-multipkg
- pkgsrc-pbulk-web
- pkgsrc-sanitizers
- pkgsrc-test-depends
- pkgsrc-ui-message
- pkgsrc-unpriv
- pkgsrc config vcs
- pkgsrc empty env
- pkgsrc gnome support
- pkgsrc installtasks
- pkgsrc mancoosi
- pkgsrc precise dependencies
- pkgsrc sensors
- pkgsrc spawn support
- pkgsrc tighten buildlink
- pkgsrc tls support in tnftp
- pkgsrc undo
- policy-routing
- policy plugins
- posix_spawn(3) chdir support
- posix suite compliance
- project/efficient-package-distribution
- pubsub-sockets
- putter pud puffs
- raidframe-discard
- raidframe-raid6
- raidframe-scrubbing
- rfc5927
- rfc6056
- routing-cleanup
- rsync
- rump-networkvisualizer
- rumpkernel-fuzzing
- safestack
- samplerate
- saslc openldap
- scalable-entropy
- scsipi-locking
- scudo
- secureplt
- sgibootloader
- sgimips
- sgimipsr10k
- shutdowntime
- simplify-ffs
- smp networking
- sso
- static-analyzers
- static-locale
- struct protosw
- sun4v
- swap-auto
- sysinst-enhancements
- sysinst-xinterface
- sysinst pkgs
- syspkgs
- system-upgrade
- syzkaller
- teredo
- tickless
- tmpfs-quotas
- tmpfs-snapshot
- tpm resume
- transparent-cgd
- triforceafl
- troff
- u-boot-ffs
- u-boot-pkgsrc
- ubsan
- ui-plugins-for-games
- update-webkit-gtk
- urtwn rtwn merge
- user-switching
- userland-san
- userland pci
- userspace-emulation-for-fun-and-profit
- valgrind
- vc4
- verify netbsd32
- virtual-box-guest-tools
- virtual network stacks
- vmwgfx
- wedgeedit
- wifi-tool
- wine amd64
- wlan-sockopts
- www
- x86-iommu
- x86 smap smep
- xen-arm
- xen-blktap2
- xen-boot-cleanup
- xen-dom0-smp
- xen-domU-pv-on-hvm
- xen-domu-acpi
- xen-domu-pvfb
- xen-drmkms
- xen-hot-add
- xen-module-support
- xen-pmap-superpage
- xen-pvscsi
- xen-pvusb
- xen-toolstack-libvirt
- xen4
- xenboot
- xfs
- xhci resume
- xhci sg
- xip
- xray
- zeroconf
- zfs
- zfs root
- puffs
- releng
- releng-todo
- releng
- reproducable builds
- root on zfs
- rumpkernel
- rust
- sandbox
- scanner
- security
- set-up raidframe
- shortcuts
- smileys
-
summits
- AsiaBSDCon 2014 NetBSD BoF
- AsiaBSDCon 2015 NetBSD BoF
- AsiaBSDCon 2016 NetBSD BoF
- AsiaBSDCon 2017 NetBSD BoF
- AsiaBSDCon 2018 BSD BoF
- AsiaBSDCon 2018 NetBSD Summit
- AsiaBSDCon 2019 NetBSD BoF
- AsiaBSDCon 2020 NetBSD BoF
- AsiaBSDCon 2025 NetBSD BoF
- EuroBSDCon 2022 NetBSD Summit
- asiabsdcon 2015 netbsd summit
- asiabsdcon 2016 netbsd summit
- asiabsdcon 2017 netbsd summit
- asiabsdcon 2026 netbsd summit
- bsdcan 2026
- eurobsdcon 2013 netbsd summit
- eurobsdcon 2014 netbsd summit
- eurobsdcon 2015
- eurobsdcon 2016
- eurobsdcon 2017
- eurobsdcon 2018
- eurobsdcon 2025 netbsd summit
- eurobsdcon 2026 netbsd summit
- symbol versions
-
?tag
- blog
- category:analyzers
- category:desktop
- category:filesystems
- category:kernel
- category:languages
- category:misc
- category:networking
- category:pkgsrc
- category:ports
- category:userland
- difficulty:easy
- difficulty:hard
- difficulty:medium
- difficulty:unknown
- easy
- funded
- gsoc
- gsoc175h
- gsoc350h
- gsoc90h
- howto
- kerberos
- kern
- needs-update
- pkgsrc
- project
- releng
- schmonz
- smp networking
- status:active
- status:done
- tier1port
- tier2port
- tier3port
- templates
-
tutorials
- How to create a screen recording with audio
- acls and extended attributes on ffs
- adobe flash
- altqd traffic shaping example
- asterisk
- atf
- bsd make
- bus space tutorial
- clang
- continuous building and testing NetBSD with buildbot
- converting usb drivers to usbwifi(9)
- cpu frequency scaling
- faking a mac address
- getting images from digital camera
- hide other user's processes
- how netbsd boots on x86
- how to access a netbsd partition under windows
- how to access webdav on netbsd
- how to balance cpu performance, temperature and power drawn
- how to build install sets, when you can't build install floppies
- how to check the smart status of your harddisk
- how to configure mercurial over https
- how to create an l2tp ipsec tunnel between an android or iphone or ios device to netbsd
- how to create bootable netbsd image
- how to enable and run dtrace
- how to enlarge raidframe
- how to gather network information on netbsd
- how to install(boot) netbsd using pxelinux
- how to install a server with a root lfs partition
- how to install laser printer samsung ml-1640
- how to install netbsd from an usb memory stick
- how to install netbsd on OVH
- how to install netbsd on a nec mobilepro 790
- how to install netbsd on a power macintosh g4 (grey)
- how to install netbsd on an apple macbook with core2duo
- how to install netbsd on hpcarm
- how to install netbsd on hpcsh
- how to install netbsd on raid1 using raidframe
- how to install netbsd on the linksys nslu2 (slug) without a serial port, using nfs and telnet
- how to mount ffs partition under linux
- how to mount iso images
- how to read css protected dvds
- how to reduce kernel size
- how to reduce libc size
- how to run maple on netbsd\i386
- how to run matlab r14.3 on netbsd\i386
- how to run netbeans ide on netbsd
- how to run oracle express on netbsd
- how to run tet framework
- how to secure samba with stunnel
- how to set up a dhcp server
- how to set up a guest os using xen3
- how to set up a samba server
- how to set up a samba server using swat
- how to set up nfs and nis
- how to set up per-user timezones
- how to setup a cvs server
- how to setup a printer with lpd
- how to setup a webserver
- how to setup cups in netbsd
- how to setup virtio scsi with qemu
- how to share an ext2 partition with linux
- how to take screenshots from the console
- how to turn off console beep
- how to update a netbsd system with haze
- how to use a samsung yepp k3 on netbsd
- how to use encrypted swap over nfs
- how to use fuse in netbsd
- how to use iscsi to support an apple time machine
- how to use lvm on netbsd
- how to use midi devices with netbsd
- how to use nokia 6230i over bluetooth as a gprs modem
- how to use snapshots
- how to use thumb mode on arm
- how to use wpa supplicant
- howto bootstrap the ePass2003 smartcard
- kerberos client
- kerberos realm
- kerberos services
- kernel secure levels
- kqueue tutorial
- latex in netbsd
- lighttpd on netbsd
- netbsd command-line cheat-sheet
- netbsd kernel runtime memory consumption
- openldap authentication on netbsd
- panic
- per file build options override
- pkgsrc
- quagga
- services
- setting up blocklistd
- speedtouch 330 adsl modem in netbsd
- sysinst translations and testing
- the netbsd system manager's manual
- tuning netbsd for performance
- unicode
- user management
- using ccache with build sh
- using git to track netbsd cvs source repository
- using pulseaudio
- using the nand emulator and chfs
-
x11
- compiz
- fluxbox
- how to blank and unblank screens on lid close\open
- how to customize keyboard mappings in x
- how to stop x11 from listening on port 6000
- how to swap cap lock with escape
- how to use anti-aliased fonts in linux emulation
- how to use gtk applications with lightweight window managers *box, e17, etc.
- how to use no bitmapped fonts
- how to use ttf fonts in xterm
- how to use wsfb uefi bios framebuffer
- userland version
-
users
- agc
- ahoka
- alnsn
- asau
- bad
- billc
- charlotte
- cirnatdan
- ?cjep
- conduct
- cryo
- cyber
- dholland
- dogcow
- erh
- haad
- hubertf
- imil
- jakllsch
- jdf
- jld
- jmcneill
- jruoho
- jun
- jym
- ?kamil
- kefren
- kim
- leot
- macallan
- maya
- mbalmer
- mef
- minskim
- mlelstv
- msaitoh
- mspo
- mw
- myproj
- ozaki-r
- plunky
- riz
- rkujawa
- roy
- ryoon
- sborrill
- schmonz
- sketch
- snj
- spz
- technibro
- tendim
- tez
- tkusumi
- tm
- uebayasi
- ?wiz
- youri
- zafer
- wifi driver state matrix
-
?wiki
- cvs
- netbsd specific
- new page
- previewing with template
- sitemap
- start
-
todo
- add calendar plugin
- apply style and layout
- be multilingual
- choose wiki software
- create page template for port-foo
- create wiki news page
- done
- enable the attachment plugin for web-editing with images
- fix "home/about/gallery/etc" bar to links
- fix cvs backend
- highlight plugin
- hook up wiki commits to www-changes@
- ikiwiki as blog
- ikiwiki as man
- implement cvs backend
- improve search
- later
- let non-developers contribute content
- make it easier to add new pages
- make toc anchor urls permanent
- merge pkgsrc wiki
- migrate content from wiki.netbsd.se
- mirror blog
- obtain wildcard ssl certificate
- push wikisrc to anoncvs
- restrict read access to certain pages
- set up demo wiki
- set up kerberos for web logins
- unformatted
- use icons to improve template look
- web-editing templates fails
- write wiki howtos
- write xml input format plugin
- web
- xfce4
- zfs
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
WIP
Otherwise known as "Cryo".
http://cryo.ws @Cryo on Twitter Cryo on irc.freenode.net Cryo+ on plus.google.com
==Experience of getting NetBSD-7 running on eeepc900==
VERY IMPORTANT *Can not configure network with WIFI with sysinst during install. Configure network will not use wpa_supplicant or wiconfig and does not differentiate between ethernet in WIFI in displaying interfaces. This gives a false impression that if you configure ath0 that it will ask for SSID, Encryption Type, and Password and generate /etc/wpa_supplicant.conf as well as add the necessary parts to rc.conf. The fact that wpa_supplicant can't accept this information from the command line and requires a conf file may be part of the problem.
IMPORTANT *DRMKMS kernel will choose other display, I guess, because the LCD will go black or weird fade to black.
NOT IMPORTANT *SDCard class 10, seems rather slow on the USB bus, like slower than on other OS I have run on it... is this not enough wakeups on the USB driver?
Quickstart with LDP daemon
Step 1: Boot an MPLS enabled kernel - see MPLS
Step 2: Run /usr/sbin/ldpd
Step 3: Add some routes to neighbors bindings and see routes being automatically tagged or just use zebra/quagga in order to do avoid manual routes
Step 4: You can look over some reports on control interface: telnet localhost 2626 - use root password - and use question mark for help
/etc/ldpd.conf example
# a default ldpd.conf
# hello-time 8;
max-label 400;
min-label 200;
command-port 2424;
# ldp-id 1.2.3.4;
# USE TCP SIGNATURE FOR THIS NEIGHBOUR - don't forget to add entries in ipsec.conf && echo ipsec=yes >> /etc/rc.conf
# add -4 1.2.3.4 1.2.3.50 tcp 0x1000 -A tcp-md5 "mypassword" ;
# add -4 1.2.3.50 1.2.3.4 tcp 0x1000 -A tcp-md5 "mypassword" ;
neighbour 1.2.3.50 {
authenticate yes;
}
Some quick info about MPLS:
You need to compile your kernel with options MPLS and psuedo-device ifmpls For pure LSR - that only switch labels without encap/decap from other protocols (e.g. INET) - you need to work on routing table, ONLY. For example:
# route add -mpls 41 -tag 25 -inet 193.28.151.97 add host 41: gateway 193.28.151.97 # route add -mpls 42 -tag 30 -inet 193.28.151.97 add host 42: gateway 193.28.151.97 # route add -mpls 51 -tag 25 -inet 193.28.151.97 add host 51: gateway 193.28.151.97
Translation of first line: if it receives an MPLS frame with label 41 forward it to INET next-hop 193.28.151.97, but switch (change) label 41 with label 25
You also need to tweak sysctl to accept and forward MPLS:
# sysctl -w net.mpls.accept=1 net.mpls.accept: 0 -> 1 # sysctl -w net.mpls.forwarding=1 net.mpls.forwarding: 0 -> 1
Verify routes with route get or better with netstat -nrT:
... MPLS: Destination Gateway Flags Refs Use Mtu Tag Interface 41 193.28.151.97 UGHS 0 37241 - 25 sk0 42 193.28.151.97 UGHS 0 0 - 30 sk0 51 193.28.151.97 UGHS 0 0 - 25 sk0
Interacting with other protocols
If you want to also decapsulate/encapsulate from MPLS to some other protocol (like INET or INET6), then you have to create an mpls interface and put in up state.
# ifconfig mpls0 create up
After that, create routes using ifa flag in order to specify the source interface (used for source IP Address of host generated packets), but route them through mpls0 interface.
# route add 204.152.190.0/24 -ifa 193.28.151.105 -ifp mpls0 -tag 25 -inet 193.28.151.97 add net 204.152.190.0: gateway 193.28.151.97
Verify the route:
# route -n get 204.152.190.0/24
route to: 204.152.190.0
destination: 204.152.190.0
mask: 255.255.255.0
gateway: 193.28.151.97
Tag: 25
local addr: 193.28.151.105
interface: mpls0
flags:
recvpipe sendpipe ssthresh rtt,msec rttvar hopcount mtu expire
0 0 0 813 344 0 0 0
sockaddrs:
or with netstat -rT:
... 204.152.190/24 193.28.151.97 UGS 0 95362 - 25 mpls0 ...
Test if it's working using traceroute -M. Notice first hop is reporting label 25.
# traceroute -M 204.152.190.12 traceroute to 204.152.190.12 (204.152.190.12), 64 hops max, 40 byte packets 1 shaitan.girsa.ro (193.28.151.97) 2.892 ms 1.957 ms 1.992 ms [MPLS: Label 25 Exp 0] 2 b4-vlan811.girsa.ro (193.28.151.82) 1.988 ms 1.961 ms 1.989 ms [MPLS: Label 27 Exp 0] 3 80.97.219.81 (80.97.219.81) 1.990 ms 1.974 ms 2.009 ms 4 vlan103.cr3-sw.buch.artelecom.net (80.97.199.1) 2.651 ms 2.280 ms 3.663 ms 5 10.0.241.189 (10.0.241.189) 33.944 ms 34.011 ms 33.869 ms [MPLS: Label 21669 Exp 0] 6 10.0.240.22 (10.0.240.22) 33.946 ms 33.689 ms 33.929 ms 7 20gigabitethernet4-3.core1.fra1.he.net (80.81.192.172) 35.930 ms 35.926 ms 35.917 ms 8 10gigabitethernet1-2.core1.par1.he.net (72.52.92.89) 43.940 ms 45.900 ms 47.916 ms 9 10gigabitethernet1-3.core1.lon1.he.net (72.52.92.33) 59.901 ms 51.888 ms 51.913 ms 10 10gigabitethernet4-4.core1.nyc4.he.net (72.52.92.241) 119.808 ms 119.780 ms 119.800 ms 11 10gigabitethernet1-2.core1.chi1.he.net (72.52.92.102) 141.755 ms 143.748 ms 149.756 ms 12 he.ord1.isc.org (209.51.161.18) 143.756 ms 143.757 ms 141.755 ms 13 iana.r1.ord1.isc.org (199.6.0.1) 145.831 ms 141.747 ms 143.762 ms 14 int-0-0-1-8.r1.pao1.isc.org (149.20.65.157) 201.653 ms 205.650 ms 201.650 ms [MPLS: Label 16005 Exp 0] 15 int-0-0-1-0.r2.sql1.isc.org (149.20.65.10) 201.663 ms 201.645 ms 201.664 ms 16 www.netbsd.org (204.152.190.12) 199.676 ms 201.652 ms 201.673 ms
See also LDP wiki page.
PAE and Xen balloon benchmarks
Protocol
Three tests were performed to benchmark the kernel:
- build.sh runs. The results are those returned by time(1).
- hackbench, a popular tool used by Linux to benchmarks thread/process creation time.
- sysbench, which can benchmark mulitple aspect of a system. Presently, the memory bandwidth, thread creation, and OLTP (online transaction processing) tests were used.
All were done three times, with a reboot between each of these tests.
The machine used:
# cpuctl list Num HwId Unbound LWPs Interrupts Last change ---- ---- ------------ -------------- ---------------------------- 0 0 online intr Sun Jul 11 00:25:31 2010 1 1 online intr Sun Jul 11 00:25:31 2010 # cpuctl identify 0 cpu0: Intel Pentium 4 (686-class), 2798.78 MHz, id 0xf29 cpu0: features 0xbfebfbff cpu0: features 0xbfebfbff cpu0: features 0xbfebfbff cpu0: features2 0x4400 cpu0: "Intel(R) Pentium(R) 4 CPU 2.80GHz" cpu0: I-cache 12K uOp cache 8-way, D-cache 8KB 64B/line 4-way cpu0: L2 cache 512KB 64B/line 8-way cpu0: ITLB 4K/4M: 64 entries cpu0: DTLB 4K/4M: 64 entries cpu0: Initial APIC ID 0 cpu0: Cluster/Package ID 0 cpu0: SMT ID 0 cpu0: family 0f model 02 extfamily 00 extmodel 00 # cpuctl identify 1 cpu1: Intel Pentium 4 (686-class), 2798.78 MHz, id 0xf29 cpu1: features 0xbfebfbff cpu1: features 0xbfebfbff cpu1: features 0xbfebfbff cpu1: features2 0x4400 cpu1: "Intel(R) Pentium(R) 4 CPU 2.80GHz" cpu1: I-cache 12K uOp cache 8-way, D-cache 8KB 64B/line 4-way cpu1: L2 cache 512KB 64B/line 8-way cpu1: ITLB 4K/4M: 64 entries cpu1: DTLB 4K/4M: 64 entries cpu1: Initial APIC ID 0 cpu1: Cluster/Package ID 0 cpu1: SMT ID 0 cpu1: family 0f model 02 extfamily 00 extmodel 00
This machine uses HT - so technically speaking, it is not a true bi-CPU host.
PAE
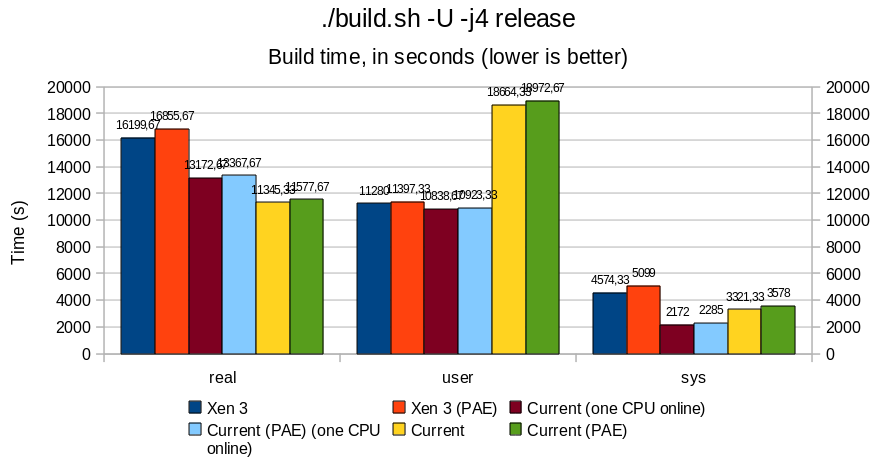
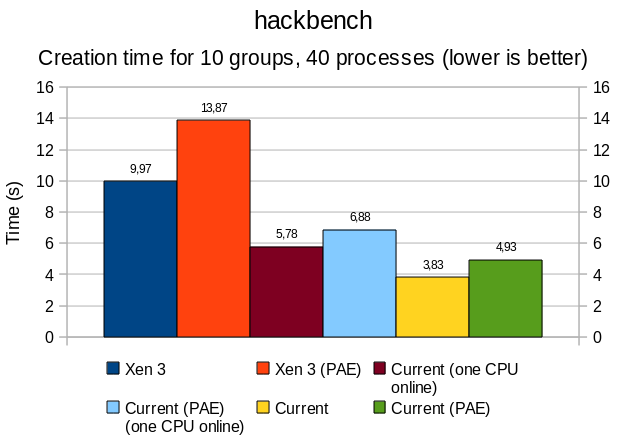
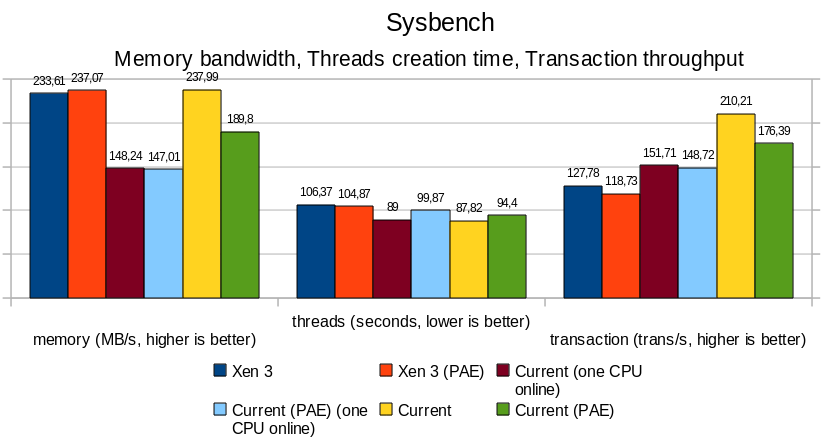
Overall, PAE affects memory performance by a 15-20% ratio; this is particularly noticeable with sysbench and hackbench, where bandwidth and thread/process creation time are all slower.
Userland remains rather unaffected, with differences in the 5% range; build.sh -j4 runs approximately 5% slower under PAE, both for native and Xen case.
Do not be surprised by the important "user" result for build.sh benchmark in the native vs Xen case. Build being performed with -j4 (4 make sub-jobs in parallel), many processes may run concurrently under i386 native, crediting more time for userland, while under Xen, the kernel is not SMP capable.
When comparing Xen with a native kernel with all CPU turned offline except one, we observe an overhead of 15 to 20%, that mostly impacts performance at "sys" (kernel) level, which directly affects the total time of a full build.sh -j4 release. Contrary to original belief, Xen does add overhead. One exception being the memory bandwidth benchmark, where Xen (PAE and non-PAE) outperforms the native kernels in an UP context.
Notice that, in a MP context, the total build time between the full-MP system and the one with just one CPU running sees an improvement by approximately 15%, with "sys" nearly doubling its time credit when both CPUs are running. As the src/ directory remained the same between the two tests, we can assume that the kernel was concurrently solicited twice as much in the bi-CPU than in the mono-CPU case.
Xen ballooning
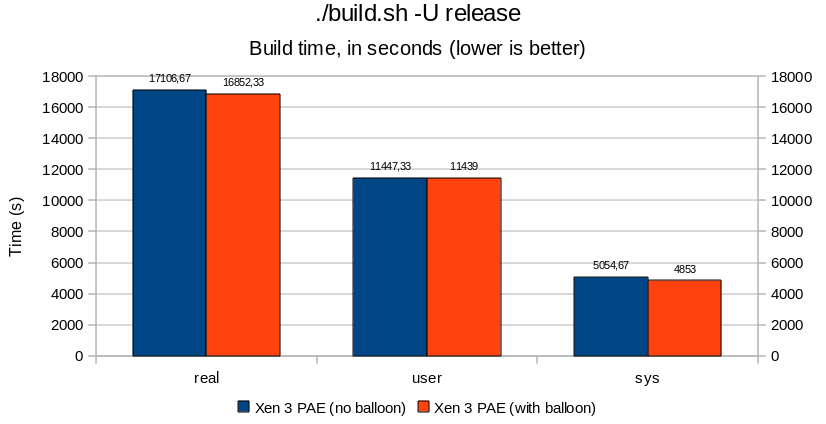
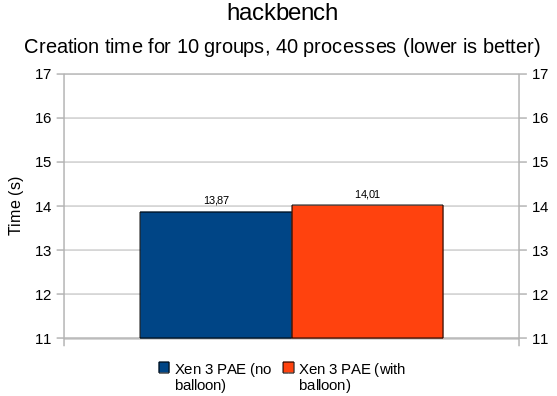
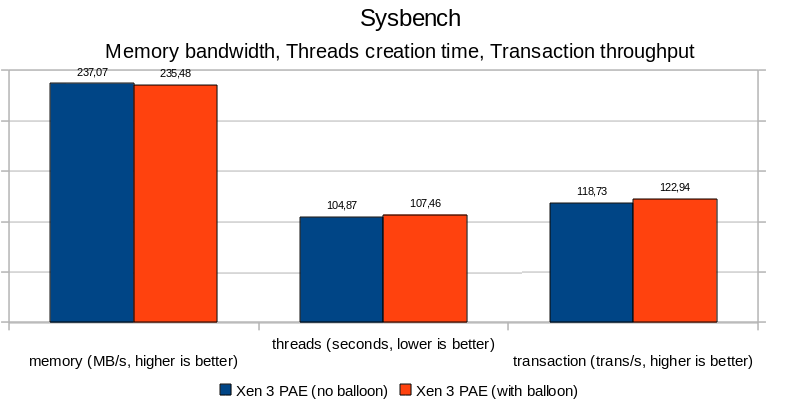
In essence, there is not much to say. Results are all below the 5% margin, adding the balloon thread did not affect performance or process creation/scheduling drastically. It is all noise. The timeout delay added by cherry@ seems to be reasonable (can be revisited later, but does not seem to be critical).
2020-2021-2022-2023-2024-2025-
2010-2011-2012-2013-2014-2015-2016-2017-2018-2019
2001-2002-2003-2004-2005-2006-2007-2008-2009
Event Updates https://www.facebook.com/NetBSD.jp
2026
Japan NetBSD Users' Group 23th annual meeting and NetBSD BoF 2026
- 2026 Jul.5 13:00-18:00 Nezu,Tokyo Univ.,VDEC
- http://www.jp.netbsd.org/ja/JP/JNUG/announce/meeting23.html
- https://www.facebook.com/events/1547607546993967
- http://www.vdec.u-tokyo.ac.jp/Guide/access.html
Open Source Conference 2026 Shimane NetBSD Booth
- Booth: 2026 Jul.11 Sat 10:00-17:00 JST (UTC+9)
- Matsue Terusa,near by JR Matsue station
- Session:
- https://event.ospn.jp/osc2026-shimane/
- Tour Guide [[]]
- togetter [[]]
Open Source Conference 2026 Kyoto NetBSD Booth & NetBSD BoF
- 2025 Aug.1 Sat 10:00-16:00 JST (UTC+9)
2025 Aug.1 Sat 16:00-16:45 JST (UTC+9) NetBSD BoF https://event.ospn.jp/osc2026-kyoto/session/2329485
Kyoto Research Park https://www.krp.co.jp/access/map.html
- https://event.ospn.jp/osc2026-kyoto/
- Tour Guide [[]]
- togetter [[]]
Open Developers Conference 2026 NetBSD BoF
- 2026 Aug.27 Sat 12:00-12:45 JST (UTC+9)
- https://event.ospn.jp/odc2026/
- Nihon Kogakuin Kamata Campus https://www.neec.ac.jp/portal/access/kamata/
- Tour Guide [[]]
- togetter [[]]
Kansai Open Forum 2026
- 2026 Nov.13 Fri-14 Sat 10:50-18:00 JST (UTC+9)
- https://www.k-of.jp/
- ATC (Asia and Pacific Trade Center)
- Nankou-kita 2-1-10, Suminoe Area, Osaka Japan.
- Tour Guide https://cdn.netbsd.org/pub/NetBSD/misc/jun/OSC/
- togetter [[]]
- youtube[[]]
Past in 2026
Open Source Conference 2026 Hokkaido NetBSD Booth and NetBSD BoF
- 2026 Jun.27 Sat 10:00-18:00 JST (UTC+9)
- NetBSD BoF 14:00-14:45 https://event.ospn.jp/osc2026-do/session/2310301
- Sapporo Business Innovation Center https://www.sapporosansin.jp/access/
- with https://www.no.bug.gr.jp/
- https://event.ospn.jp/osc2026-do/
- Tour Guide https://cdn.netbsd.org/pub/NetBSD/misc/jun/OSC/OSC2026hokkaido.pdf
- togetter https://posfie.com/@ebijun/p/3QUhHvw
Open Source Conference 2026 Sendai NetBSD Booth & BoF
- Booth: 2026 Jun.6 Sat 10:00-18:00 JST (UTC+9)
- BoF: 2026 Jun.6 16:00-16:45 JST (UTC+9) https://event.ospn.jp/osc2026-sendai/session/2302526
- Tohoku Computer College https://tcc.ac.jp/outline/access/
- https://event.ospn.jp/osc2026-sendai/
- Tour Guide https://cdn.netbsd.org/pub/NetBSD/misc/jun/OSC/OSC2026sendai.pdf
- togetter https://posfie.com/@ebijun/p/NqQAv0o
- Youtube https://www.youtube.com/watch?v=4rscUOfx0Tw
Open Source Conference 2026 Nagoya NetBSD Booth & NBUG BoF
- 2026 May.23 Sat 10:00-18:00 JST (UTC+9)
- BoF 2026 May.23 Sat XX:00-XX:45 JST https://event.ospn.jp/osc2026-nagoya/session/2296979
- Nagoya Trade & Industry Center https://www.nipc.or.jp/fukiage/sub/visitor-access.html#around
- with http://nagoya.bug.gr.jp/
- https://event.ospn.jp/osc2026-nagoya/
- Tour Guide https://cdn.netbsd.org/pub/NetBSD/misc/jun/OSC/OSC2026nagoya.pdf
- togetter https://posfie.com/@ebijun/p/lpOl8KO
- https://www.facebook.com/NetBSD.jp/videos/2440408836782072
- https://www.slideshare.net/ao_kenji
Open Source Conference 2026 Kagawa
- 2026 Apr.18 Sat 10:00-18:00 JST (UTC+9)
- BoF 2026 Apr.18 Sat XX:00-XX:45 JST [[]]
- e-topia kagawa https://www.e-topia-kagawa.jp/
- https://event.ospn.jp/osc2026-kagawa/
- Tour Guide https://cdn.netbsd.org/pub/NetBSD/misc/jun/OSC/OSC2026kagawa.pdf
- togetter https://posfie.com/@ebijun/p/TARTFTx
- https://speakerdeck.com/tsutsui/osc2026kagawa NetBSD+UIAPduino+PSG
Open Source Conference 2026 Tokyo/Spring NetBSD Booth & BoF
- Booth: 2026 Feb.27-28 Fri-Sat 10:00-16:00 JST (UTC+9)
- BoF: 2026 Feb.27 Fri 15:15-16:00 JST (UTC+9) [[]]
- KOMAZAWA UNIVERSITY SHUGETSUKAN https://www.komazawa-u.ac.jp/english/access/
- https://event.ospn.jp/osc2026-spring/
- Tour Guide https://cdn.netbsd.org/pub/NetBSD/misc/jun/OSC/OSC2026tokyospring.pdf
- togetter https://posfie.com/@ebijun/p/QvR9Tx9
- https://speakerdeck.com/tsutsui/osc2026tokyo-spring NetBSD+RPI+PSG
Open Source Conference 2026 Osaka NetBSD Booth & BoF
- 2026 Jan.31 Sat 10:00-17:00 JST (UTC+9)
- NetBSD Bof:12:00-12:45
- Osaka Sangyo Sozoukan https://www.sansokan.jp/map/
- https://event.ospn.jp/osc2026-osaka/
- Tour Guide https://cdn.netbsd.org/pub/NetBSD/misc/jun/OSC/
- togetter https://posfie.com/@ebijun/p/Vfaj1UC
- https://speakerdeck.com/tsutsui/osc2026osaka NetBSD+RPI+PSG
Monthly
Nagoya *BSD Users' Group monthly meeting
Current my job mission
- SOUM Corporation http://www.soum.co.jp,TOKYO
- Support Open Science Framework in Japan
- Job offer: via SOUM Corporation.
make NetBSD booth and presentation around Japan area.
- Open Source Conference https://www.ospn.jp/
- OSPN.jp Youtube https://www.youtube.com/c/OSPNjp/search?query=NetBSD
- Report on http://mail-index.netbsd.org/netbsd-advocacy/tindex.html
- https://github.com/ebijun/NetBSD/blob/master/Guide/OSC/OSC2024.rst
- https://github.com/ebijun/NetBSD/blob/master/Guide/OSC/OSC2023.rst
- https://github.com/ebijun/NetBSD/blob/master/Guide/OSC/OSC2022.rst
- https://github.com/ebijun/NetBSD/blob/master/Guide/OSC/OSC2021.rst
- https://github.com/ebijun/NetBSD/blob/master/Guide/OSC/OSC2020.rst
- https://github.com/ebijun/NetBSD/blob/master/Guide/OSC/OSC2019.rst
- https://github.com/ebijun/NetBSD/blob/master/Guide/OSC/OSC2018.rst
- https://github.com/ebijun/NetBSD/blob/master/Guide/OSC/OSC2017.rst
- https://github.com/ebijun/NetBSD/blob/master/Guide/OSC/OSC2016.rst
- https://github.com/ebijun/NetBSD/blob/master/Guide/OSC/OSC2015.rst
NetBSD machines in Japan
NetBSD Raspberry PI Images
- https://github.com/ebijun/NetBSD/blob/master/RPI/RPIimage/Image/README
- ftp://ftp.netbsd.org/pub/NetBSD/misc/jun/raspberry-pi/
- https://github.com/ebijun/NetBSD/blob/master/Guide/RPI/RPIupdate2023.rst
- https://github.com/ebijun/NetBSD/blob/master/Guide/RPI/RPIupdate2022.rst
- https://github.com/ebijun/NetBSD/blob/master/Guide/RPI/RPIupdate2021.rst
- https://github.com/ebijun/NetBSD/blob/master/Guide/RPI/RPIupdate2020.rst
- https://github.com/ebijun/NetBSD/blob/master/Guide/RPI/RPIupdate2019.rst
- https://github.com/ebijun/NetBSD/blob/master/Guide/RPI/RPIupdate2018.rst
- https://github.com/ebijun/NetBSD/blob/master/Guide/RPI/RPIupdate2017.rst
- https://github.com/ebijun/NetBSD/blob/master/Guide/RPI/RPIupdate2016.rst
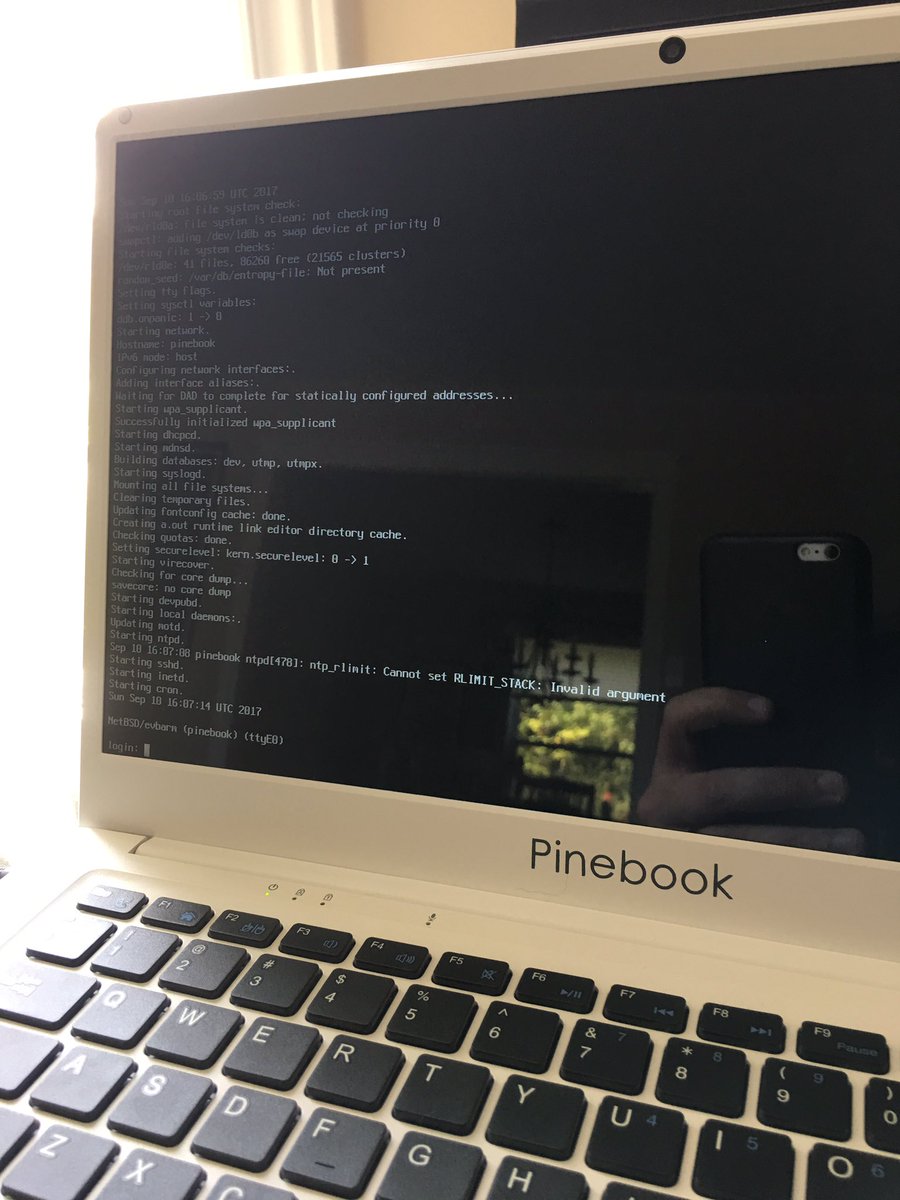
NetBSD/pinebook status
update NetBSD.jp Facebook Page
update togetter Page
NetBSD Travel Guide for NetBSD booth
Japan NetBSD Users' Group
- http://www.jp.NetBSD.org/
- https://github.com/NetBSDjp/htdocs
- http://www.soum.co.jp/~jun/2014maps.pdf
- http://www.slideshare.net/junebihara18/osc100th-asiabsdcon
Nagoya *BSD Users' Group
- http://nagoya.bug.gr.jp/
- usermeeting/month