
PAE and Xen balloon benchmarks
Protocol
Three tests were performed to benchmark the kernel:
- build.sh runs. The results are those returned by time(1).
- hackbench, a popular tool used by Linux to benchmarks thread/process creation time.
- sysbench, which can benchmark mulitple aspect of a system. Presently, the memory bandwidth, thread creation, and OLTP (online transaction processing) tests were used.
All were done three times, with a reboot between each of these tests.
The machine used:
# cpuctl list Num HwId Unbound LWPs Interrupts Last change ---- ---- ------------ -------------- ---------------------------- 0 0 online intr Sun Jul 11 00:25:31 2010 1 1 online intr Sun Jul 11 00:25:31 2010 # cpuctl identify 0 cpu0: Intel Pentium 4 (686-class), 2798.78 MHz, id 0xf29 cpu0: features 0xbfebfbff cpu0: features 0xbfebfbff cpu0: features 0xbfebfbff cpu0: features2 0x4400 cpu0: "Intel(R) Pentium(R) 4 CPU 2.80GHz" cpu0: I-cache 12K uOp cache 8-way, D-cache 8KB 64B/line 4-way cpu0: L2 cache 512KB 64B/line 8-way cpu0: ITLB 4K/4M: 64 entries cpu0: DTLB 4K/4M: 64 entries cpu0: Initial APIC ID 0 cpu0: Cluster/Package ID 0 cpu0: SMT ID 0 cpu0: family 0f model 02 extfamily 00 extmodel 00 # cpuctl identify 1 cpu1: Intel Pentium 4 (686-class), 2798.78 MHz, id 0xf29 cpu1: features 0xbfebfbff cpu1: features 0xbfebfbff cpu1: features 0xbfebfbff cpu1: features2 0x4400 cpu1: "Intel(R) Pentium(R) 4 CPU 2.80GHz" cpu1: I-cache 12K uOp cache 8-way, D-cache 8KB 64B/line 4-way cpu1: L2 cache 512KB 64B/line 8-way cpu1: ITLB 4K/4M: 64 entries cpu1: DTLB 4K/4M: 64 entries cpu1: Initial APIC ID 0 cpu1: Cluster/Package ID 0 cpu1: SMT ID 0 cpu1: family 0f model 02 extfamily 00 extmodel 00
This machine uses HT - so technically speaking, it is not a true bi-CPU host.
PAE
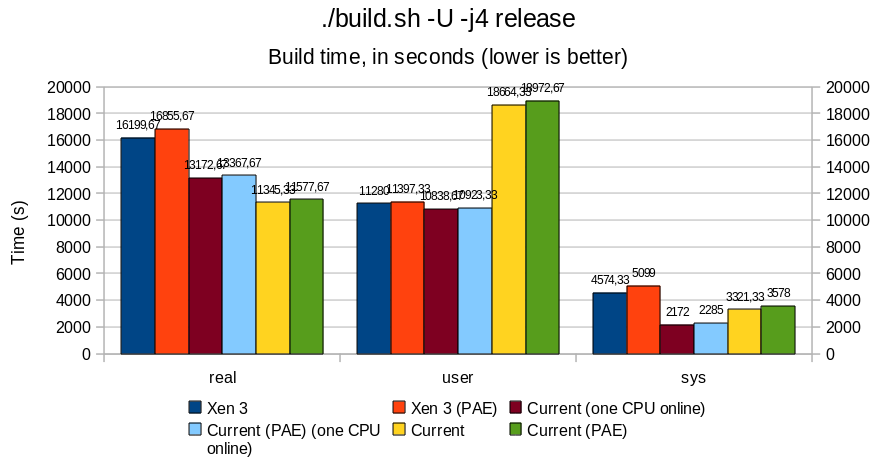
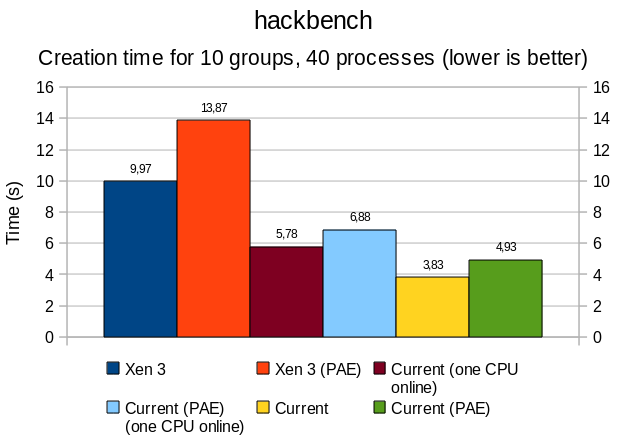
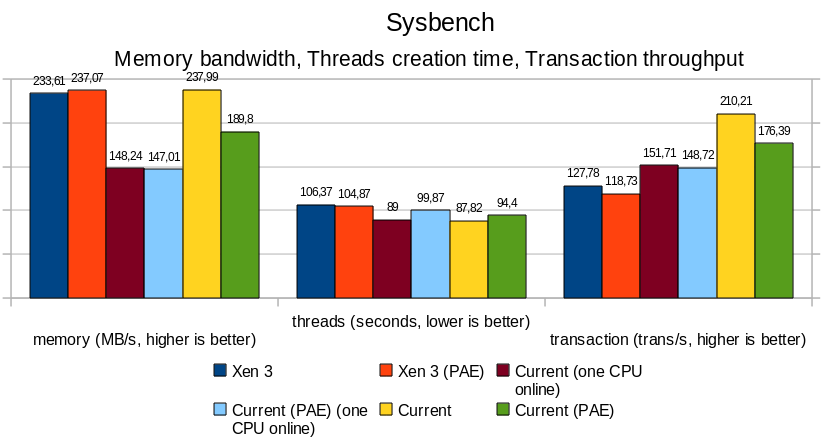
Overall, PAE affects memory performance by a 15-20% ratio; this is particularly noticeable with sysbench and hackbench, where bandwidth and thread/process creation time are all slower.
Userland remains rather unaffected, with differences in the 5% range; build.sh -j4 runs approximately 5% slower under PAE, both for native and Xen case.
Do not be surprised by the important "user" result for build.sh benchmark in the native vs Xen case. Build being performed with -j4 (4 make sub-jobs in parallel), many processes may run concurrently under i386 native, crediting more time for userland, while under Xen, the kernel is not SMP capable.
When comparing Xen with a native kernel with all CPU turned offline except one, we observe an overhead of 15 to 20%, that mostly impacts performance at "sys" (kernel) level, which directly affects the total time of a full build.sh -j4 release. Contrary to original belief, Xen does add overhead. One exception being the memory bandwidth benchmark, where Xen (PAE and non-PAE) outperforms the native kernels in an UP context.
Notice that, in a MP context, the total build time between the full-MP system and the one with just one CPU running sees an improvement by approximately 15%, with "sys" nearly doubling its time credit when both CPUs are running. As the src/ directory remained the same between the two tests, we can assume that the kernel was concurrently solicited twice as much in the bi-CPU than in the mono-CPU case.
Xen ballooning
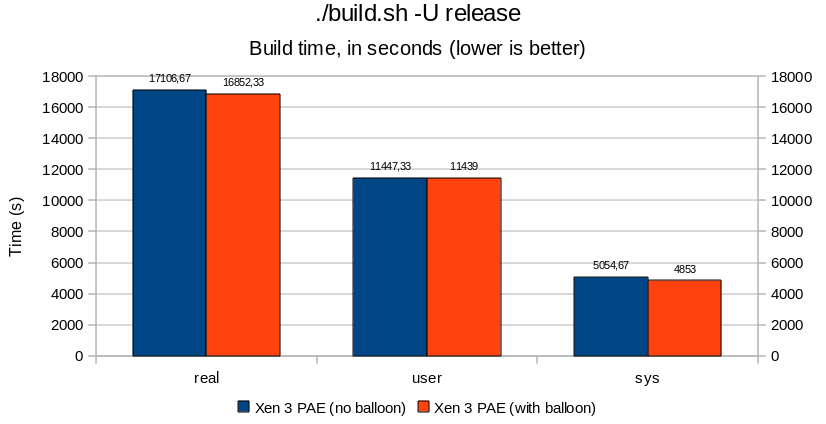
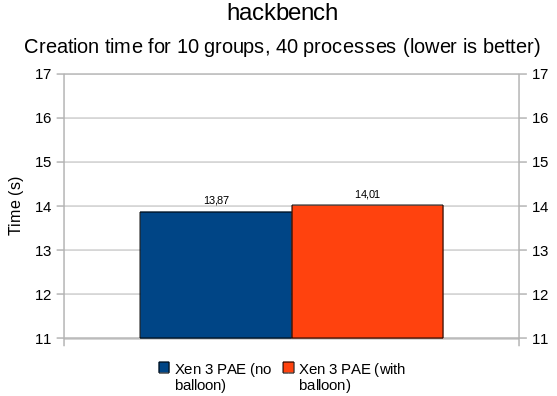
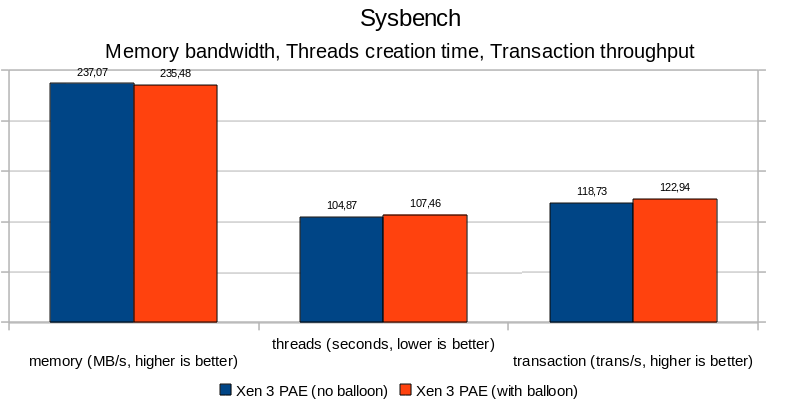
In essence, there is not much to say. Results are all below the 5% margin, adding the balloon thread did not affect performance or process creation/scheduling drastically. It is all noise. The timeout delay added by cherry@ seems to be reasonable (can be revisited later, but does not seem to be critical).